


新規求人を1本立ち上げるたびに、媒体ごとのフォーマットに合わせて求人票を書き直し、ペルソナごとにスカウトテンプレートを練り上げる。気づけば半日が消えている。採用担当の方であれば、こうした作業に追われた経験があるのではないでしょうか。
近年、生成AIを採用業務に取り入れる動きが広がっています。ただし、汎用チャットに毎回ノウハウを書き起こすやり方では、改善のサイクルがどうしても1対1の会話で途切れてしまいます。コンテキスト(参照する情報)を整備し、その上で動かせるエージェント型ツールであれば、採用担当の暗黙知をそのまま「現場の手」として再利用できる。クラシル株式会社の採用担当・須賀氏が、その実装工程をすべて公開しました。
2026年4月28日、株式会社overflow 代表取締役CEOの鈴木裕斗が進行を務め、Claude Codeで採用業務の作業時間を約4分の1まで圧縮した実装工程を須賀氏に語っていただくウェビナーを開催しました。先行公開されたnoteは大きな反響を呼び、当日は約60分のあいだに止まらない数の質問が寄せられました。
本記事では、Claude Codeを採用に活かす発想から、ペルソナ・マスター求人票・媒体別変換・スカウトテンプレート生成までの4ステップ、75%削減という結果の背景にある「改善ループの高速化」、セキュリティと運用設計、そしてこれから始める方への助言までを再構成してお届けします。
採用担当が手を動かす時間の大半は「候補者と向き合う時間」以外
――鈴木:まずは須賀様が今回Claude Codeで取り組まれた領域について教えてください。採用担当者の業務全体のうち、どこにフォーカスされたのでしょうか。
須賀様:採用担当は「面接をしている」イメージを持たれがちですが、大半は候補者と向き合う時間以外で構成されているのではないかと感じています。定型作業としてのエージェントとのコミュニケーションやCSとの打ち合わせ、事務作業としての日程調整・合否連絡・数字集計、そしてドキュメンテーション領域として求人票の作成や修正、スカウトテンプレート、ペルソナや技術広報の整備。実際に候補者と向き合う以外の時間に多く使われている方は少なくないと捉えています。

このなかでも、今回はドキュメンテーション領域、特に求人票の作成・修正と、スカウトテンプレートの2つに優先的に取り組みました。新規求人の立ち上げや既存求人の修正は、採用に関わる方であれば必ず一定の頻度で発生しますし、公開求人数×利用媒体数の更新が必要になるので、シンプルに作業量が多い領域なのです。
弊社も昨年だけで、節約アプリの「クラシルリワード」が「レシチャレ」に名称変更となり、社名変更も重なる大きな転換があった年でした。これに合わせて公開中の全求人を書き直す必要があり、コーディネーターの方が数営業日を使って対応してくださいました。業務効率化の観点でAI活用のインパクトが最も大きい領域だと判断し、ここに優先的に取り組んでいます。
暗黙知をMarkdownへ移植する ── Claude Codeを採用に活かす発想
――鈴木:Claude Codeが採用業務に向いていると感じられたポイントはどこにありますか。
須賀様:Claude CodeはAnthropic社が提供するエージェント型のコーディングツールで、自然言語で指示するとファイルを読んで書いて実行し、タスクを完了させるツールです。他のチャット系AIと違うのは、事前にコンテキスト(参照する情報)を整備しておけば、それを読み込んだ上で結果を返してくれる点。長々とプロンプトを書かなくても求めるアウトプットが出てくるのが、最大の特徴だと考えています。

採用に活きると感じる理由は、暗黙知が多く、定型作業が多い領域だからです。自分の中で言語化できる暗黙知をMarkdownファイルに書き起こしてコンテキストにする。つまり、自分の脳内をドキュメントとしてClaude Codeに移植する形で整備していけば、Claude Codeが自分の代わり、現場担当者の代わりに手を動かす状態が作れるのです。採用業務とは相性が良いと、実際に取り組んでみて実感しています。
ペルソナ→マスター求人票→媒体別変換→スカウト ── 4ステップで採用を組み立て直す
――鈴木:全体像として、4つのステップで設計されたとお聞きしています。それぞれのステップで何をされているのか教えてください。
須賀様:採用ペルソナの設計から始まり、マスター求人票を作成し、媒体別フォーマットへ一括変換し、各媒体に最適化されたスカウトテンプレートを生成する。この4ステップを一連の流れとして組み上げました。これまで人が人力でコツコツやってきた部分を、Claude Codeで一括生成できるよう自動化しています。

ステップ1:ペルソナ設計
最初のステップはペルソナ設計です。求人票やスカウトを作るうえで「誰に何を届けるか」が最も重要であり、その核になるのがペルソナだと考えています。
弊社の場合は、ハイヤリングマネージャーと一緒に作成したジョブディスクリプション(JD)を読み込ませることで、複数パターンのペルソナを自動で設計する仕組みを作っています。たとえばキャリア成長志向のエンジニア、スペシャリスト志向型のエンジニア、ワークライフバランスや家庭を重視するエンジニアといった形で、3パターン程度を言語化します。このペルソナをハブに、以降の求人票やスカウトの生成を進めていきます。

リクルーターがやるべきことは、ペルソナの仮説をゼロから立てることよりも、候補者と会いながら解像度を上げ、ペルソナのドキュメントをチューニングしていくことだと捉えています。面談で得たインサイトを反映してペルソナの解像度が上がるほど、求人票以降の成果物の品質も底上げされる仕組みになっています。
ステップ2:マスター求人票の作成
次に、各媒体の求人票のハブとなるマスター求人票を1つ作成します。読み込ませる素材は、JDの原本、ステップ1で作ったペルソナ3パターン、技術ブログ記事のリストをまとめた articles.md、会社概要、カルチャー、VMV、網羅的な会社説明書など。これらを事前にコンテキストとして整備しておけば、「適切なマスター求人票を作ってください」という指示ひとつで仕上げてくれる状態になっています。

ステップ3:媒体別フォーマットへの一括変換
マスター求人票ができたら、各媒体のフォーマットに合わせた求人票を一括生成します。媒体ごとに求人票作成のフォーマットは異なるため、ひとつずつ手動で登録すると相当な手間がかかります。事前に各媒体のフォーマット定義を .md ファイルとして用意し、convert job posting のようなコマンドを打つだけで一括変換が走るようにしました。

たとえば、セクション数が少なく共感重視・ストーリー性を重視するペルソナが多い媒体には、「何をやっているのか」「なぜやるのか」「どんなことをやっているのか」「こんなことをやります」というセクション構成に合わせて、文体まで自動で調整します。Claude Codeが各媒体のフォーマット定義を読み込み、「この媒体のセクション構成はこうなっているのだから、こう書こう」と判断して生成してくれる状態です。
実際にやってみて、新規求人立ち上げのインパクトが最も大きかった部分です。これまでは媒体ごとに「この情報はどこに入れるのが適正か」を毎回考える必要がありましたが、フォーマット定義を事前に読み込ませることで、その思考プロセスをまるごと省略できるようになりました。
ステップ4:スカウトテンプレートの生成
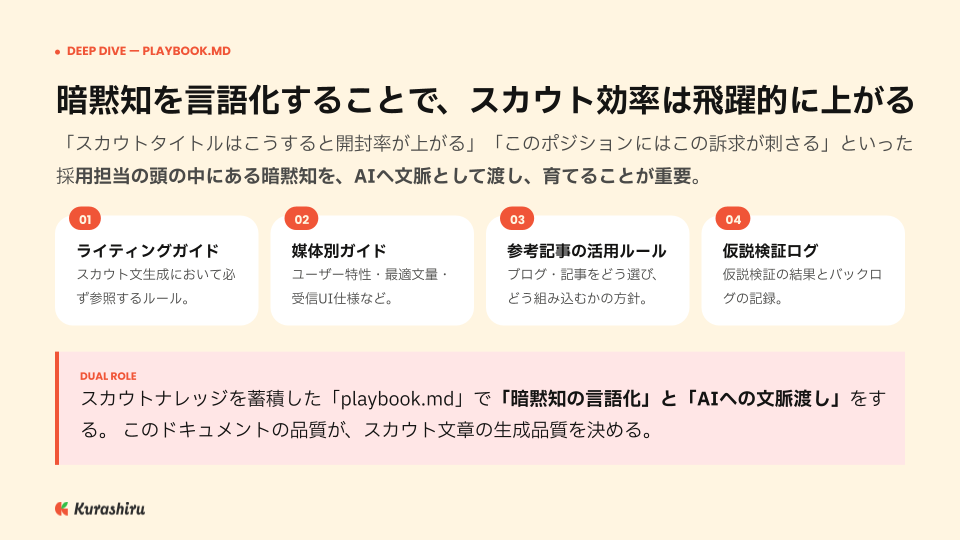
求人票だけでなく、スカウトテンプレートの生成にも同じ思想を持ち込んでいます。スカウトのノウハウ──ファーストビュー文字数、件名のトーン、開封率が高い件名の傾向、再送設計など──をこれまで個人のドキュメントツールに貯めていたものを、専用の playbook.md というローカルドキュメントに移し、継続的に蓄積しています。
ここに加えて、求人票、ペルソナ、articles.md、ペルソナに合う記事のURL、過去のテンプレートなどを読み込ませて、各社・各媒体に最適化されたテンプレートを一括生成しています。

ただし、ここで肝になるのは「全部を作ってもらうのではなく、あくまでテンプレートを作ってもらう」という線引きです。「なぜあなたに送ったのか」「あなただから届けたい情報」といった、いわゆる YOU メッセージの領域に関しては、いまも自分やエンジニアが手書きをして送る運用を分けています。固定的に届けたい情報のテンプレートをClaude Codeで生成し、個別の YOU 部分は人間が担う。これが現時点の最適解だと捉えています。
75%削減の正体 ── 自動化ではなく「改善ループの高速化」が効いた
――鈴木:実際に運用されて、どれくらいのインパクトが出ているのでしょうか。
須賀様:新規求人の立ち上げに関しては、これまで全工程をきっちりやろうとすると半日ほどかけていた感覚でしたが、現在は1時間程度に圧縮できています。感覚値としては約75%の削減です。

ただ、本当にインパクトが大きかったのは作業時間そのものよりも、改善サイクルの高速化のほうだと捉えています。以前から PDCA は意識していましたが、訴求を1回変えると各媒体すべてのスカウトと求人票を書き直す必要があり、率直に言ってやり切れていなかったのが実情です。AIで自動化・短縮されたことにより、改善サイクルは1週間単位、スカウト文の改善であれば毎日ベースで回せるようになりました。
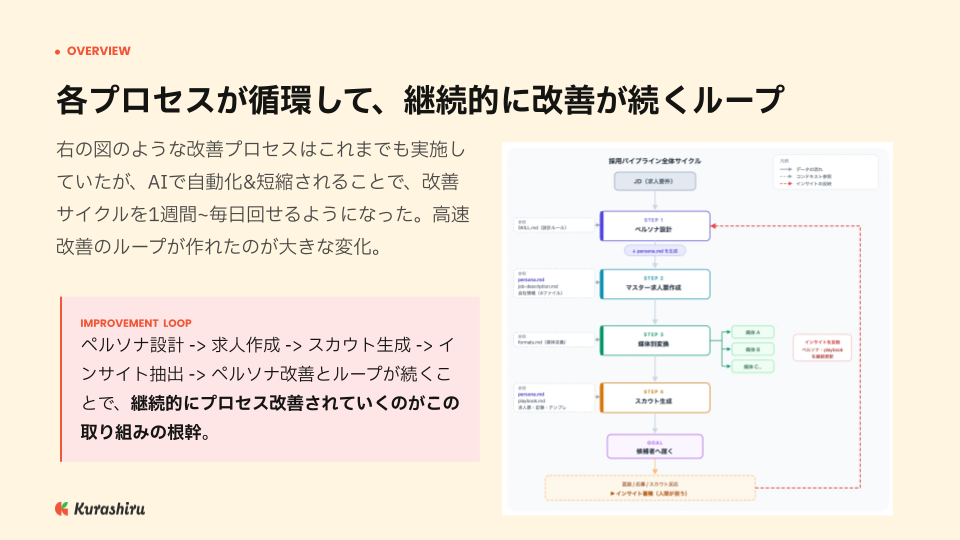
特にスカウトを送って候補者と話したり、レジュメを実際に拝見していると、「こういうことを考えているのだろうな」という仮説が見えてきます。それを playbook.md というナレッジドキュメントに蓄積してスカウトを生成する。この循環を続けるだけでも、毎日改善ができている感覚があります。実際に既読率が向上した実績も出ており、改善ループの高速化こそアウトカムへのインパクトが大きかった部分だと感じています。
もう一つ気づいたことは、ペルソナの改善がすべての品質を底上げするという点です。ペルソナがずれていると、誰に何の情報を届けるのかという軸自体がずれてしまいます。面談での会話、エージェントとのやり取り、スカウトでのレジュメ確認──こうした一次情報を継続的に読み込ませてペルソナを育てていくことで、求人票やスカウトのアウトプット品質が上がっている実感があります。ペルソナの改善は人間がやり続けるべき領域だと、現時点で確信しています。

――鈴木:自動化のその先に何を置くか、という話にもつながりますね。
須賀様:本質は「採用を自動化する」ことではなく、「候補者体験を上げること」だと捉えています。ペルソナに対してこの情報を届けるべきなのに届いていない、という気づきを早くAIに入れて反映する。情報の非対称性を減らすことで、候補者は欲しい情報を取って、自社をきちんと理解した上で意思決定や応募ができるようになります。

人間としては、会って会話して心を動かすという行為はこれまでと変わりません。そこで学んだインサイトをAIに渡して素早く反映するスピードを上げていく。これが現時点での、人間とAIの採用活動における住み分けとしてしっくり来ています。
セキュリティ・権限管理・チーム共有 ── 採用領域でAIを動かす運用設計
――鈴木:HRでClaude Codeを活用するうえで、セキュリティ面はどう整備されたのでしょうか。求人作成は個人情報に関わらないとはいえ、ATSやスカウト媒体まで踏み込むと話が変わってきます。
須賀様:会社全体としては、経営陣がすでに積極的に使い始めていたため、トップダウンで「まずは使おう」というモメンタムが生まれていました。情報漏洩などのセキュリティリスクへの整備は、上層と直接対面でやり取りしながら設計するスピード感で進めてくださり、AIに詳しいエンジニアも巻き込みながら整備されたので、非エンジニアとしてはスムーズに取り組める環境でした。
HR文脈では、ATSのAPI利用ガイドラインを上層やAI担当のレビューを経てチームに共有・落とし込むフローを踏んでいます。こうした取り組みで、セキュリティ状態を担保しながら活用を進めています。

――鈴木:補足させてください。セキュリティはレイヤーで整理するとわかりやすいと考えています。第1層はどのLLMをどのプランで使うか。ChatGPT、Claudeなど、エンタープライズで契約するかどうかで情報の制限は変わります。第2層が MCP などでツール接続を行うフェーズです。ATSや人事管理システムと接続する場合、誰でもフリーに接続できる状態にすると、給与情報まで参照できてしまうことも起こり得る。部署単位の権限設計まで踏み込んで決めていく必要があります。須賀様の運用では、MCPは申請制にされているとお聞きしました。
須賀様:はい、デスクトップアプリから繋げるコネクターは中央管理した上で繋げる状態になっています。ただし、MCPで繋いだ先のSaaSがアクセスできる権限のものしかClaude Codeは拾えないため、SaaS側の権限設定が適切に行われていれば、Claude Codeが触れる情報も自然に制約されます。データを蓄積しているSaaSの権限管理が適切かどうかは、論点として大きいと捉えています。
――鈴木:チーム内でのファイル・スキルの共有はどうされていますか。
須賀様:いまはGoogleドライブを使っています。Gitによるバージョン管理は学習コストが高いと判断して見送りました。運用ハードルの課題は残っていますが、現時点では、.md ファイルを変更したらClaudeのフックを使って変更内容をSlackで通知し、該当メンバーにメンションする仕組みを作っています。重要なスキル .md や会社のコンテキストファイルについては、修正前にSlackで承認を取るフローも組み込み、疑似的なGit運用として回しています。
ソーシングと送信はあえて自動化しない ── 利用規約とヒューマン・イン・ザ・ループ
――鈴木:候補者ピックアップ(ソーシング)やスカウトの送信そのものは、技術的に自動化できそうにも見えます。あえて自動化されていないのには理由があるとお聞きしました。
須賀様:ソーシングを自動化できないかは私自身も調べましたが、結論として送信は自分で行っています。理由は2つです。
ひとつは利用規約です。各スカウト媒体を運営する企業が、AIを活用した送信を禁止する方向で利用規約をアップデートしている動きが見えてきました。基本的にAI送信を行うと媒体側が制限する方向に動いているため、利用規約に反する選択はしないという意思決定です。
もうひとつはヒューマン・イン・ザ・ループの観点です。送信をミスると、シンプルに個人情報の漏洩につながりますし、Aの方に送るはずがBの方に送ってしまうのはインシデントとして大きい。送信の最終地点には、人間が責任を取れる介在を残すべきだと捉えています。それ以外の作業を全部自動化するというのが、現時点の方針です。
――鈴木:レジュメ情報はテンプレート生成に渡されているのでしょうか。
須賀様:現時点ではテンプレートを渡していません。テンプレート全体は、最初に設計したペルソナの3パターンに合わせて生成しているため、ペルソナレベルでのパーソナライズには寄っています。実際にお会いしたりレジュメを拝見して気づいたことは persona.md の改善に反映していくので、ペルソナ自体が実在の人物像に近づくほど、結果としてパーソナライズが進む構造になっています。
1ヶ月の投資で景色が変わる ── これから始める採用担当者へ
――鈴木:須賀様が現在の精度でアウトプットを出せるようになるまで、どれくらいの期間が必要でしたか。
須賀様:実用レベルに到達するまでは約1ヶ月かかりました。2月末ぐらいに本格的に始めて、3月いっぱい使い倒し、月末には想定のアウトプットが出せるようになった感覚です。残業や休日も含めてかなり集中して取り組みましたが、最初に覚えることが大きなレバレッジになると判断して、ずっと触り続けていました。
――鈴木:時間の作り方も気になるところです。日中の業務で皆さん忙しいなか、どう向き合われたのでしょうか。
須賀様:3月は「基本的に全部Claudeでやろう」と決めて仕事をしていました。求人票を作りたいなら、こういう求人を作りたいという指示を全部Claude Codeに打ち込んで作ってもらう。最終的に手で直す部分があるかもしれませんが、求めるアウトプットが出たら、その会話履歴の情報を参考にして「スキルにして保存しておいて」と指示します。次回以降はそのスキルを読み込めば、最終的にできたアウトプットと同等のものを再現してくれるようになる仕組みです。

最初は全工程をClaude Code経由で会話しながら終わらせて、それをスキルという手順書にまとめておく。次回以降はそのスキルだけで進むので、業務効率化が一気に進みます。「自分の手でやっていることを全部Claudeにやらせる」と決めて1ヶ月続けた、というのが正直なところです。
――鈴木:「お願いするより自分でやった方が早い」と感じる場面が多いと思いますが、そこを堪えて続けるのが分岐点になりそうですね。
須賀様:AIに任せるというのは部下に仕事を任せるのと近い感覚です。最初は遅くても、まずはAIにやってもらう。その意識でやり切りました。いまではスカウト文章を含め、自分よりも質の高いアウトプットが一発で出てくる場面が増えていて、率直に言って投資効果は大きかったと実感しています。
――鈴木:AI活用初心者の1人採用担当者が始めるとして、おすすめの入口はどこになりますか。
須賀様:直近、Claudeのデスクトップアプリが大きくアップデートされ、ターミナル版との差分がかなり縮まりました。最初はデスクトップアプリから始めるのが入りやすいと考えています。ターミナルやエディタを入れなくても十分始められます。そのうえで「フォルダ構成が見えないとコンテキストが作りづらい」と感じるようになったら、エディタやターミナルを導入していく順序で問題ありません。
――鈴木:CLAUDE.md など、コンテキストファイルはどのように育てていますか。
須賀様:率直に言うと、CLAUDE.md 自体はあまり育てていません。最近はスキル .md の側に手順や参照情報を定義しておけば十分動くという議論もあり、私もそちらの方針で運用しています。
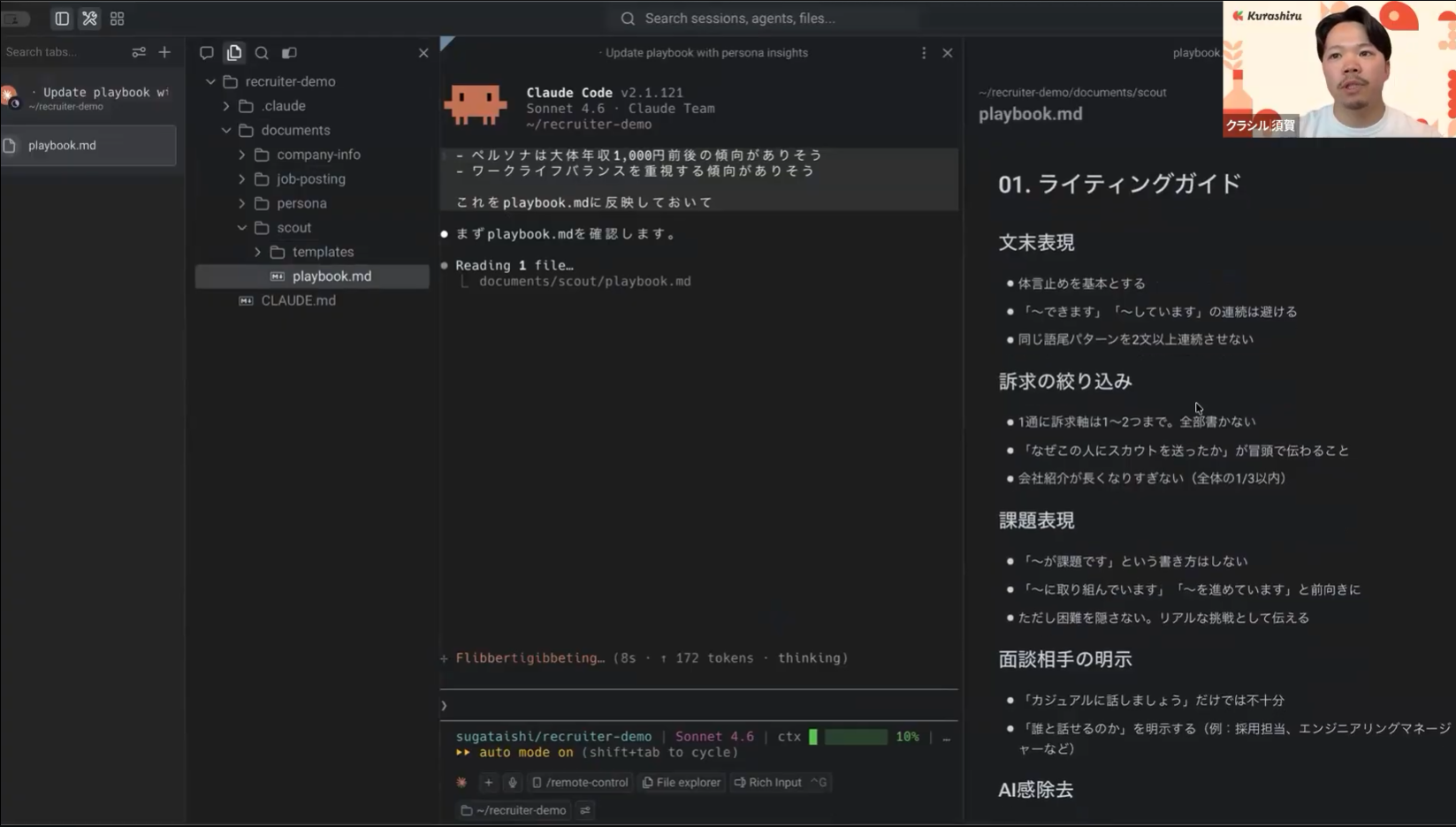
――鈴木:インサイトの蓄積はどんな粒度で書かれているのでしょうか。
須賀様:たとえばスカウトを送りながら「このペルソナは年収1000万円前後かもしれない」「ワークライフバランス重視の傾向がありそう」といったメモをその場で取り、Claudeに「playbook に反映しておいて」と指示します。そうするとスカウト中に感じたことが、playbook.md というナレッジドキュメントに自動で蓄積されていく。面談後に得た学びも同じやり方で取り込んでいるので、次回スカウトを生成する際にはこの情報が参照されるイメージで運用しています。
ChatGPTなど他のチャット型AIとの違いも、ここに集約されます。チャット型では毎回ノウハウをチャット文に書きねてから指示する必要があり、1対1の会話で完結してしまう。Claude Codeはコンテキストを把握したうえで人間と同じように作業してくれるので、別物として捉えています。
――鈴木:各部門からの採用要件の回収は、どう運用されていますか。
須賀様:要件の回収は人間がやっている領域です。弊社ではハイヤリングマネージャーがJDを書いてくれるので、そこに採用要件が乗ります。リクルーターが深掘りして情報を追加する流れです。要件の周辺情報、たとえば実際の仕事内容を知りたい場合には、技術ブログプラットフォーム内の関連記事を探してもらい、求人票に追加するといった使い方をしています。
――鈴木:補足すると、コンテンツ資産がまだ少ない会社では、社員へのインタビューが入り口として有効だと考えています。1時間でも構わないので、業務内容や事業内容を聞き出す。台本はClaudeで作れるので、ミーティングレコードのAIツールで文字起こしを残し、それをナレッジとして読み込ませる。インタビュー期間を1週間設けて一気に集めるやり方は、実際にやってみると効率が高いはずです。

須賀様:まったく同じ意見です。一次情報をどれだけ拾えるかが、結局はアウトプットの質を決めると実感しています。
最後に、Offersでは「AIと採用」をテーマにしたカンファレンスを7月に開催予定です。今回のような実装ノウハウや最先端の活用事例をキャッチアップしたい方は、ぜひご注目ください。
おわりに
採用業務へのAI活用は、ツールを入れること自体ではなく、自分の暗黙知をどれだけ言語化してAIに渡せるか、そして改善ループをどれだけ速く回せるかにかかっています。
須賀様の「自分の手でやっていることを全部Claudeにやらせる」という1ヶ月の集中投資は、その後の運用フェーズで何倍にもなって返ってきました。ペルソナを育て、候補者体験を上げるためにAIを使う──この発想転換が、これからの採用担当の新しい標準になっていくはずです。
明日からの一歩として、まずは自分の手作業をひとつ、Claudeに渡せる形で言語化するところから始めていただければ幸いです。















