


「採用にAIを活用したいが、どこから始めればいいかわからない」——そう感じる採用担当者は少なくありません。AIツールの選択肢は増える一方で、何をどう使えば実際の成果につながるのかは、まだ現場で手探りが続いているのが実情です。
2025年4月17日、株式会社HR Force 事業開発企画 ゼネラルマネージャーの石川 徹氏と、overflow 代表取締役CEO 鈴木裕斗によるウェビナー「採用でAIはどう使う!?〜採用×AIに挑む2名が本音で語る現場のリアルと成功事例〜」が開催されました。
HR Forceは創業8年目、HRとデジタルのかけ合わせで中小企業の採用を支援してきた企業です。石川氏自身も業務外でAIを活発に活用されています。Offersはエンジニア採用に特化したハイクラスプラットフォームで、スカウト自動生成・求人生成など複数のAI機能を提供しています。
ウェビナーでは「ターゲットペルソナの設計」から「スカウトメッセージ」「求人原稿」「候補者評価」まで、採用ファネル全体にわたるAI活用のリアルが語られました。本記事ではそのポイントをまとめてお届けします。
まず揃えたい前提——ターゲットとペルソナ、採用AIを使う前に混同しがちな2つの違い
――鈴木:採用現場で「ターゲット」と「ペルソナ」という言葉はよく使われますが、石川さんはこの2つをどう使い分けていますか?

石川様:明確な違いがあります。ターゲットは定量データをもとにしたターゲティングの手法で、主にグループの分類や広告の配信枠の設計に使うものです。一方、ペルソナは定量データに加えて定性データが入ります。悩みや価値観、考えていること——それらを含めて、グループではなく個人レベルで落とし込んでいくものです。
たとえば、私自身を例に出すと、「川崎市在住の男性30代」というのがターゲットのレベルです。「石川徹39歳、川崎市在住、週末はフロンターレを応援している」というのがペルソナのレベルです。これくらい情報の粒度が違います。
.png)
石川様:具体的な例でいうと、「首都圏在住」というターゲット設定から、「杉並区の3LDKのマンションに奥様と小学生のお子さん2人で暮らし、時間がない、育児との両立が課題」というところまで落とし込むのがペルソナです。さらに「YouTubeで時短動画系を見る」という情報があって初めて、「長尺ではなく短尺動画で訴求しよう」という戦術につながります。
.png)
この粒度の違いを理解しておくことが、採用でAIを使いこなす上での出発点です。採用面接の質問設計や、求人のコピー、スカウト文の作成に重要なのはターゲットではなくペルソナです。このペルソナというものをどれだけ具体的にイメージできるかによって、AIのアウトプット精度が相当変わります。
採用ペルソナの精度を決める2つのデータ——高パフォーマー分析と離職者データの「足し引き」
――鈴木:採用ペルソナを作る際にAIを使うとして、どんなデータを用意すればいいのでしょうか?
.png)
石川様:マーケティングペルソナと採用ペルソナは、取得するデータがまず違います。顧客インタビューを取りながらペルソナを作っていますという場合、採用ペルソナとしては外れてしまう可能性があります。
採用ペルソナに必要なのはこの2つです。ひとつは社内の高パフォーマーの分析——1on1のデータや業績、その人の行動の癖といったものをデータ化します。もうひとつは離職者のデータ——離職者データをいかにデジタル化できるか。高パフォーマーのデータで足し算、離職者データで引き算をすることで、非常に強いデータセットが作れます。
――鈴木:やはり元のデータが重要ということですよね。良いスカウトや求人を作るためのペルソナを作るには、データを溜めることが第一前提になりますか?
石川様:そうですね。一般的なデータを出力するのはもう誰でもできてしまうので、差別化するポイントは自社のユニークデータをどれだけ溜められるか、そしてそれを分類された状態でAIに渡せるかどうかです。
たとえば私のデモで出てきたストーリーも、実はお客様にご提案して成果が良かったケースの要素を分解してAIに読み込ませています。こういった自社の実績データが蓄積されていることで、汎用的なアウトプットとは違う精度が出てきます。
.png)
石川様:AIを使ったペルソナ生成のフローとしては、まず事前知識をAIにインストールします。事前知識を与えることでAIが動きやすくなり、アウトプットがブレなくなります。その後「ペルソナを生成してください」と指示すると、共感マップの形でペルソナが作られ、最終的に個人のプロファイリング——たとえば「吉田正太さん32歳」という具体的な人物像まで落とし込まれます。さらにその人物の転職ストーリーまで作ることで、クリエイティブのイメージが具体化していきます。求人票を読み込ませて「ペルソナを作ってください」と言うだけで、この精度まで上がってきます。
スカウト工数80%削減の裏側——「ワンポチ」を支える複数LLM連携の設計思想
――石川様:さっきのBefore Afterも実は2〜3回壁打ちしてブラッシュアップしていましたが、Offersはワンポチでできるとのこと。何が違うんですか?
.png)
鈴木:候補者のレジュメと自社の求人を読み込んで、共通項を洗い出し、「なぜあなたにスカウトを送るのか」の部分を自動生成します。
今日はデモとして弊社CTO大谷のOffersプロフィールを使いました。求人を選択してAI生成ボタンを押すと、大谷のレジュメからキャリアや開発経験が、求人から活用できるスキルやポジションの詳細が引っ張り出され、「なぜあなたがこの求人に合うのか」を説明する文面が自動生成されます。このまま送るもよし、ここにペルソナを踏まえたエモーショナルな味付けを加えるとさらに良いスカウトになります。実績として、工数の80%削減、返信率が2.4倍になった企業様が出ています。
.png)
石川様:これは本当に助かります。私も数年前にエンジニアを採用しようとして、相当苦労しました。言語やスキルの話が全然わからない中で、何とか勉強しながらスカウトを書いていたので、猛勉強しなくてもちゃんとしたスカウト文章が取れるというのは、当時の自分に教えてあげたかった機能です。
――石川様:ちなみに今日のデモでのBefore Afterも、実は私のプロンプトも2〜3回対話しながらブラッシュアップしています。ワンポチで出るOffersとは、何が違うんですか?
.png)
鈴木:やっていることは同じです。石川さんが2〜3回壁打ちしていることを、裏では複数のLLMを組み合わせてやっています。最初はChatGPTで構造整理をして、次にClaudeで肉付けをして、最後にGeminiでアウトプットのスタイルを調整する——という形で組み合わせています。ユーザーからはワンポチに見えますが、裏では石川さんの3ポチ分くらいを処理している感じです。皆さんの工数負担を削減するために、それを内側に閉じ込めています。
石川様:AIが何人もいるのに、それが見えないというのがすごい。「存在を感じさせない」というのがメリットだと思いますが、本当にそれが実現されていますね。
ペルソナを当てるだけで求人原稿はここまで変わる——Before/Afterで見る「感情訴求」への転換
――鈴木:求人でも、ペルソナありとなしでは出力がかなり変わるんですか?
石川様:同じプロンプトを投げても、これだけ変わります。今日は高級自動車の求人原稿を例に出しました。ペルソナなしで作った原稿は、皆さんの想像を超えないような、汎用的なキーワード訴求の文章です。そこに詳細なペルソナを当てていくと、突然エモくなります。「高級車を通して、人生の一台を」みたいな、高級ブランドのキャッチコピーのような表現が入ってくる。ペルソナが持つ考え方や価値観に対してちゃんとハマる訴求文章が生成されてきます。
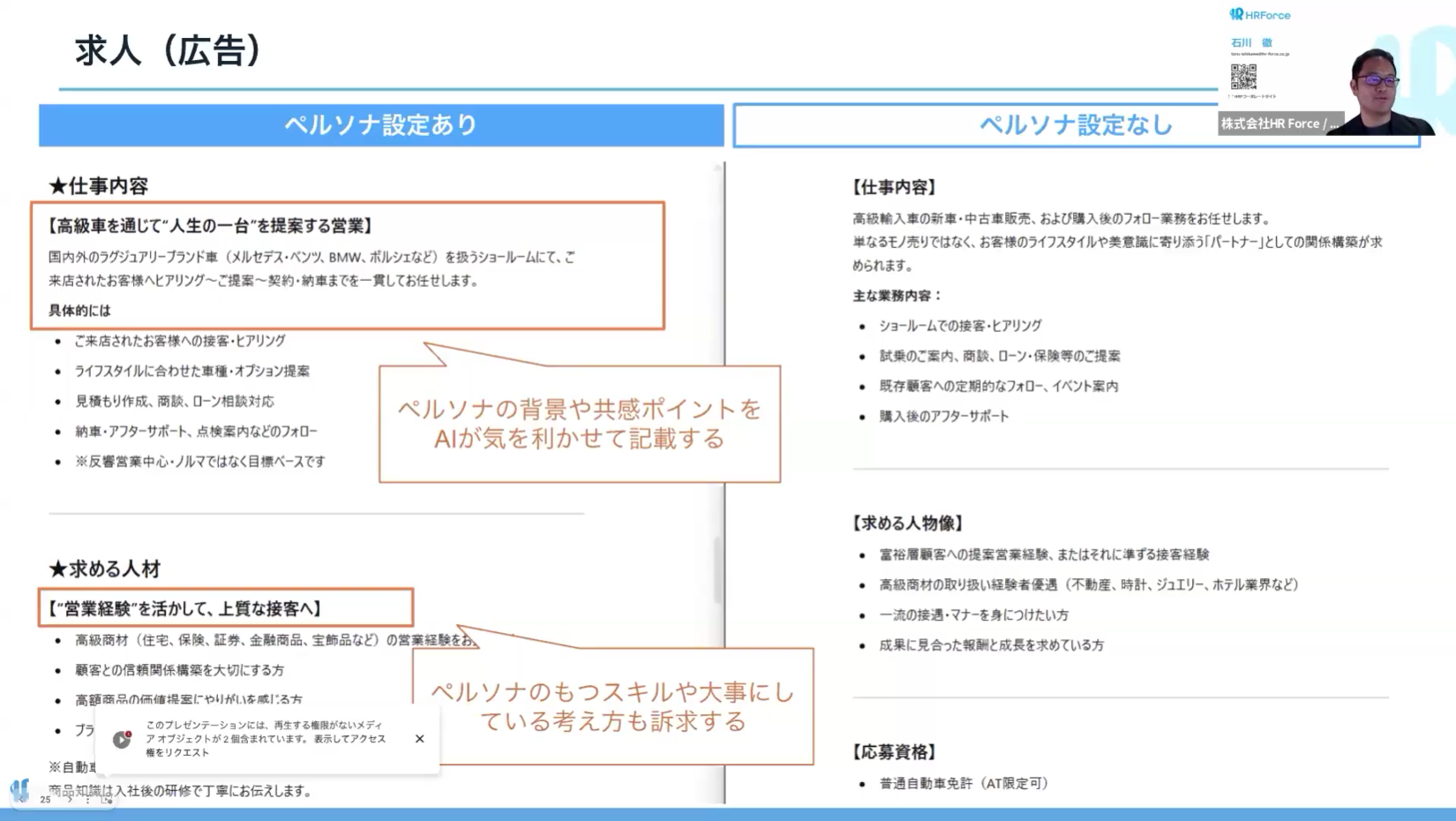
ターゲットだと「共通のキーワードで訴求しましょう」というキーワード広告的な発想になりますが、ペルソナを使うと「物語のアプローチで感情に刺す」というコンテンツ戦術に落とし込まれます。
――鈴木:スカウトで志望度を上げた候補者が、さらにエモい求人を見る。この連鎖が候補者体験を最適化するということですね。
石川様:そうです。スカウトでエモく刺した後に志望順位が上がった状態で求人を見せられると、さらに上がる。その連鎖をずっと作り続けることができます。Offersでは、企業情報や事業内容を入力すると、求人に合わせて事業の成長性やプロダクトの面白さを自動生成する機能も提供しています。ペルソナを組み合わせることで、この連鎖がより強くなります。
「心を動かすのは人間、ファクトを取るのはAI」——面接での役割分担の設計
――鈴木:面接でAIはどう活用できますか?
.png)
石川様:面接は大きく「挨拶→アイスブレイク→質問→クロージング」という流れです。この中で一番大事なのがアイスブレイクです。ペルソナを作り、それをもとにスカウトを送っている場合、アイスブレイクでもその定性情報を活かして候補者さんの自己開示を引き出すことができます。この「心を動かす」という部分、志望順位を上げるという部分は、やはり人間がやるべきだと強く思っています。
.png)
一方でAIが得意なのは情報の取得です。感情が関わらないところです。面接が盛り上がった後「あの人何言ってたっけ」となってしまうことって、ありませんか?私は結構あるタイプで、そうなるとミスマッチが起きてしまう。AIに会話をデータとして捉えてもらうことで、冷静な情報の列挙を取得できます。人の得意分野とAIの得意分野を有効に合わせた面接ができるというわけです。
.png)
石川様:デモでは候補者のレジュメと会話データ(デモでは実際の個人情報ではなくモデルデータを使用)をAIに投げると、採用基準との一致度やコメントが生成されます。私自身の若い頃のレジュメをモデルデータとして使って検証してみたんですが、HR Forceの営業担当として評価させてみたら、総合スコア6点をいただけました。評価中はさすがにドキドキしましたが(笑)。
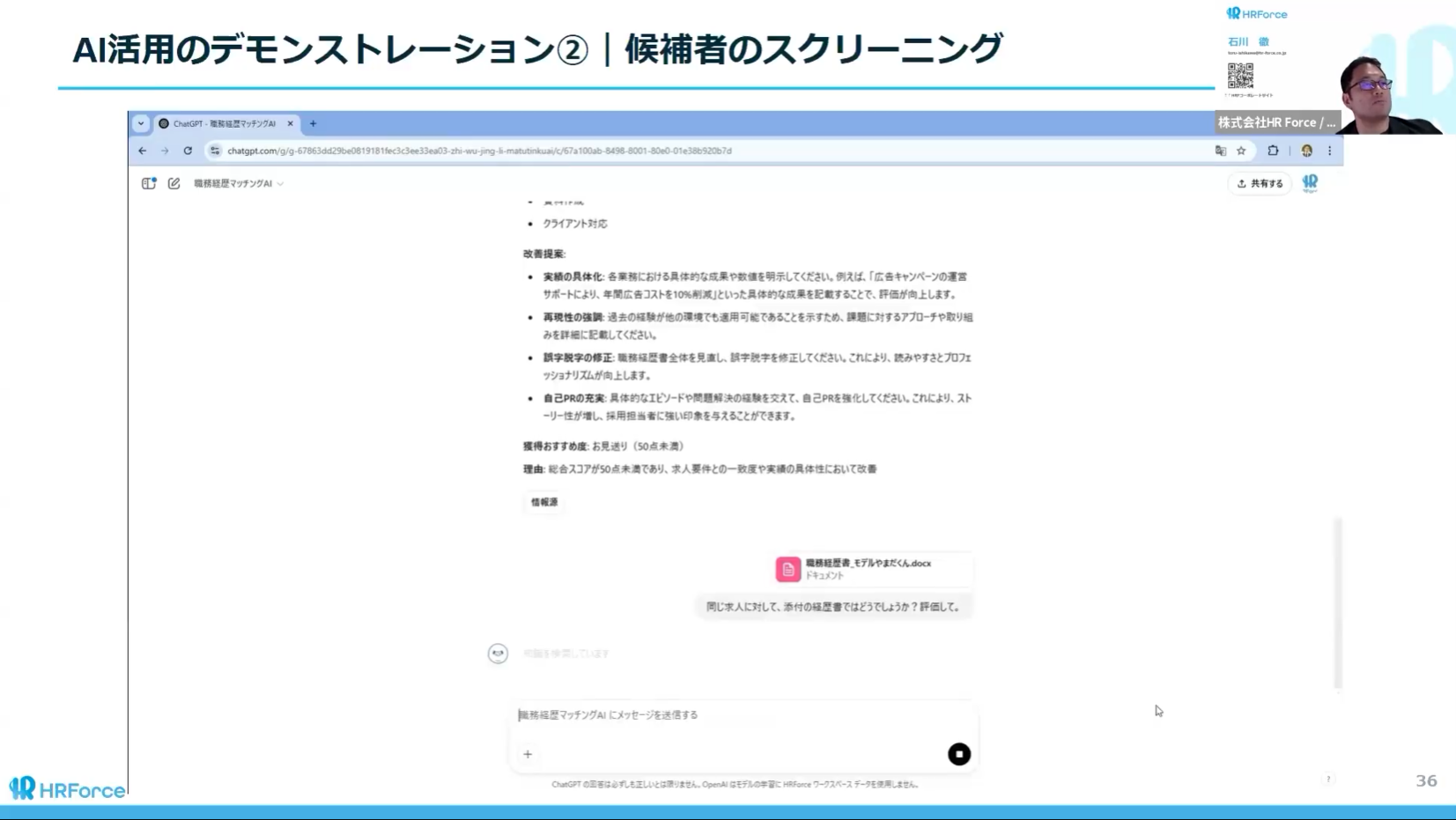
面接前にAIに聞いておく、あるいは面接後に会話データを読み込ませる——どちらのタイミングでも使えます。これによって、1人で面接をしていても2人目の意見として参照できますし、評価データがレポートとして残るので、リーダーからマネージャーへの引き継ぎが「見ればわかる」状態になります。
.png)
――鈴木:採用現場でよくある「経営者やマネージャーからなんとなく不合格と言われるが、理由が抽象的でフィードバックしにくい」という問題も、AIの評価レポートがあれば解決しそうですね。
.png)
石川様:まさにそうだと思います。AIが出した基準という「共通の軸」があれば、人事とマネージャーが衝突するのではなく、「AIの評価を改善しよう」という議論になる。非常に建設的で、フィードバック工数も下がります。
AIの評価が引き出す「心理的安全性」——普段黙っているメンバーが大量フィードバックを入れた理由
――鈴木:AIが出した評価に対して、チームはどう反応するんですか?
石川様:これが意外と面白くて、AIが出した評価には、みんながめちゃくちゃ意見を言うんですよ。上司が出した評価だと、メンバーとしては「くつがえすのは難しい」と感じる。でもAIが出したからというだけで、「AIがやったことだから叩いても大丈夫」という安心領域ができるらしく、フィードバックが大量に入ってきます。
実際に体験したエピソードがあって、自分で作った提案書を「AIが作った」と言ってメンバーに出したことがあります。そうしたら普段黙っているメンバーが大量にフィードバックしてきて、けっこうへこみました(笑)。でもそこで「これは使える」と思いました。評価や提案のように、みんながやや言いづらいと感じるものはAIを経由させたほうが、精度が上がるし組織が動きやすくなる。採用評価でも同じことが起きます。
――鈴木:AIを通すことで、むしろ引き出しやすくなるということですね。
石川様:そうです。AIがやったという媒介があることで、心理的安全性が高まる。採用評価だけでなく、いろんな場面で意識して使ってみると面白いと思います。
.png)
Q&Aハイライト:離職者データ・個人情報・ツール活用
離職者データとして使えるシグナルは?
参加者から「離職者データはどんな項目を集計すべきか」という質問が寄せられました。
石川様:従来のタレントマネジメントシステムに入っているような定量データ(異動履歴・評価履歴)に加えて、今はもっと曖昧なデータでも活用できます。1on1の音声データや、会議での発言内容、弊社で言えばミツカリ(カルチャーフィットアセスメントツール)の回答の経年変化なども有効です。たとえば「100%リモートワークだった社員を50%に変更したとき、エンジニアのマネージャー職の満足度が急低下した」というシグナルが出れば、それが離職予兆データになります。こういった会話データや音声データも今の時代は十分なデータになります。
候補者の個人情報をAIに入れていいのか?
石川様:弊社グループでは、個人情報は基本的にLLMに投げないというルールにしています。投げる場合は氏名や会社名をマスキングすることを推奨しています。社内のAI使用ガイドラインをすでに作り始めている企業も増えています。AIを適切に使えるかどうかを評価指標に入れ、給与と紐づけている企業もあると聞きます。
鈴木からも補足がありました。MCPやRAGといった技術を使うことで、社内の情報を外部に出さずにAIを活用する方法も出てきているので、検索して調べてみてほしいとのことです。
複数LLMの役割分担
スカウト・求人生成で複数のLLMを組み合わせているという話に対して、詳細を聞かれた鈴木は次のように説明しました。
鈴木:ChatGPT、Claude、Geminiを使っています。ChatGPTはまずレジュメの基本情報を構造整理します。次にClaudeで肉付けをしてストーリー仕立てにする作業をします。最終的にGeminiでアウトプットのスタイルを決める——という流れです。ただ日々改善しているので、LLMの組み合わせは変わり続けています。
おわりに
採用のフルファネルにAIを活用するとき、最初に決めるべきことはペルソナの設計だと石川氏と鈴木は一貫して語りました。「一般的なデータはもう誰でも出せる。差別化は自社のユニークデータにある」——この視点でデータを積み上げていくことが、スカウトの返信率を上げ、求人への応募率を改善し、面接のミスマッチを防ぐ起点になります。AI活用の出発点として、まず高パフォーマーと離職者のデータ整備から始めてみてはいかがでしょうか。















